Loading...

Loading...
A skilled and engaged team of 4-6 students looking to disrupt current industries and practices through artificial intelligence, machine learning, and other disruptive technologies.
Below you can see the projects we’ve been working on, and click on any one to learn more.


This project explores reinforcement learning in Rocket League, training an AI agent to perform complex in-game maneuvers such as ball control, shooting, and dribbling. Using deep reinforcement learning techniques, the agent improves over time, competing against human players and demonstrating advanced gameplay strategies.
Reinforcement Learning (RL) plays a crucial role in Artificial Intelligence (AI), particularly in complex decision-making environments. Rocket League provides an ideal platform for testing and refining RL algorithms due to its dynamic, physics-based gameplay. Despite advancements in RL, awareness in both academic and professional circles remains limited. Showcasing successful RL applications in popular games like Rocket League serves as an engaging method to educate and inform the public about RL’s potential. By highlighting practical RL implementations, this project contributes to inspiring further research and development, bridging the gap between theoretical AI advancements and real-world applications.

To mitigate problems with noisy electroencephalogram (EEG) data and financially inaccessible medical-grade EEG devices, we present 2 NLP-inspired attention-based neural networks to improve classification accuracy.
About 15 million people worldwide suffer from conditions, including locked-in syndrome, that entirely restrict their movement. Currently, thought-classification models predominantly utilize professional-grade brain-computer interfaces (BCIs), costing upwards of $25,000, rendering them unaffordable for many. Furthermore, these existing models typically achieve accuracy levels ranging from 70-80%. Our primary goal, therefore, is to create a model leveraging a more accessible 8-channel EEG setup that attains accuracy comparable to existing professional systems.
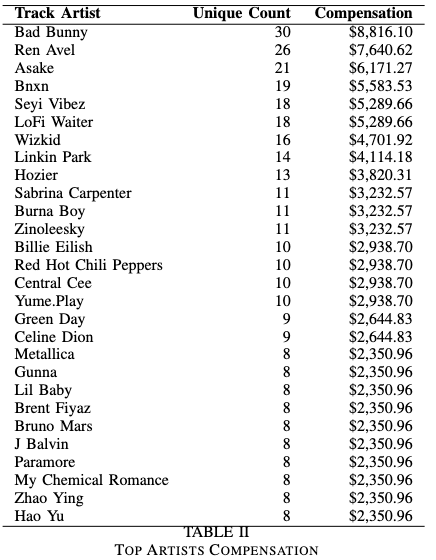
The paper aims to address the challenge of unauthorized use of copyrighted music in generative music AI by proposing a framework that ensures creators receive fair compensation while maintaining transparency in data usage. Throughout our paper, we introduce methods that combine federated and split learning with privacy-preserving techniques such as digital watermarking, fingerprinting, and algorithmic similarity analysis to detect and track copyrighted material without exposing sensitive data. Their results demonstrate that integrating these detection techniques with a levy-based compensation model can significantly reduce potential litigation costs from a projected $350 million to around $22.5 million in a case study, paving the way for a more equitable ecosystem for both AI developers and music creators
This project tackles the issue of adapting copyright law for generative AI systems, and developing reliable and safe methods of detecting copyrighted music in datasets. We believe that our proposed framework could fundamentally change the way that copyright holders and AI developers work together, by introducing ethical business practices through integrating advanced watermarking and fingerprinting techniques into AI training processes. We ensure that artists receive fair compensation while safeguarding intellectual property rights. This approach not only fosters transparency in data usage but also creates a win-win scenario for both AI developers and music creators.
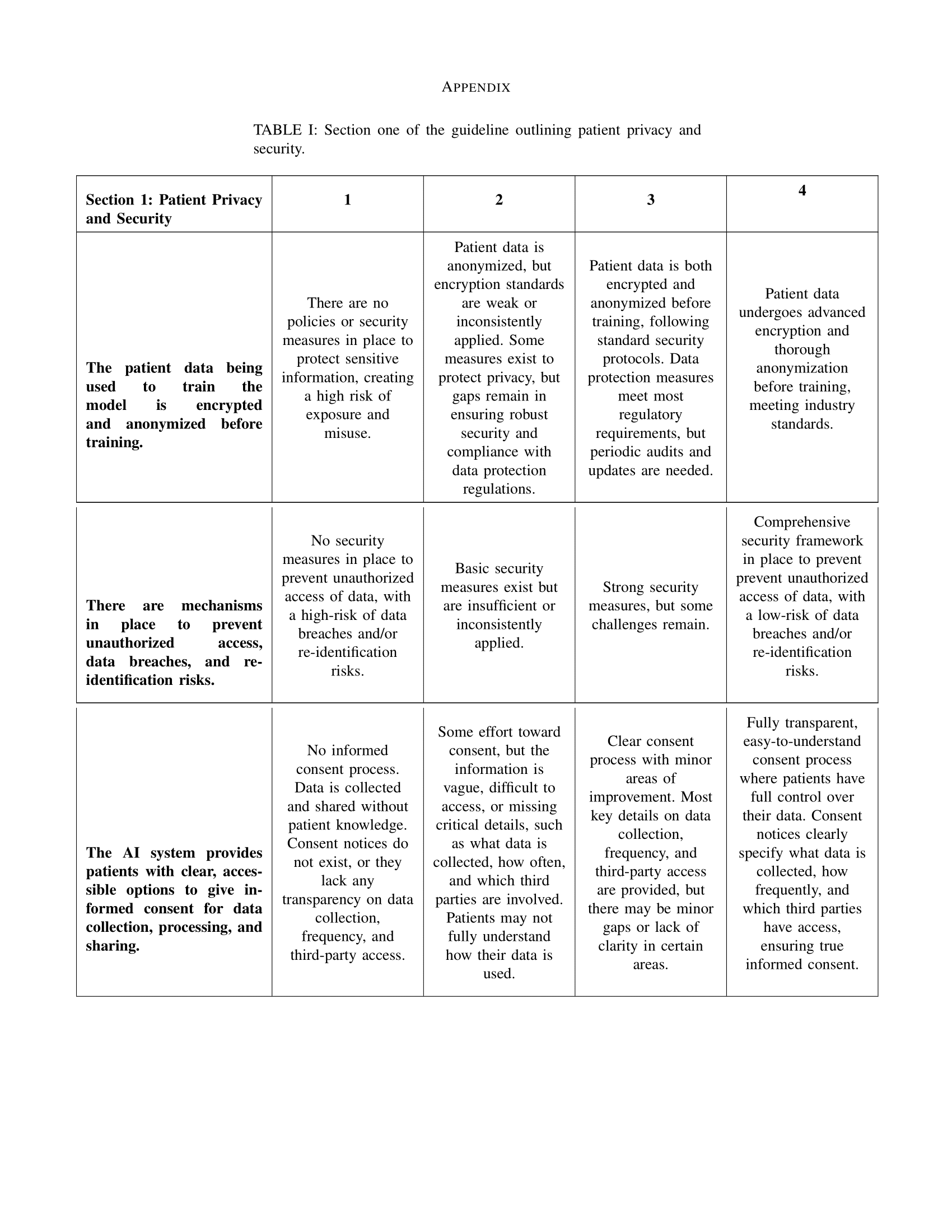
The increasing usage of artificial intelligence in MRI disease classification and diagnosis presents several ethical impli- cations related to patient privacy, data security, and responsible use. This paper will review some current use cases of AI-based MRI image classification models and propose a framework for ethics policymakers and medical information officers to ensure patient safety and responsible usage of AI in clinical settings.
This project proposes a general guideline that policymakers and clinicians are encouraged to consult before deciding to implement an AI-based software in a clinical setting. By following these guidelines, anyone looking to implement an AI-based software can ensure that it will be used ethically and will protect patient privacy and sensitive information.

The project explored various models (3D Convolutional Neural Network (CNN), 2D CNN + LSTM, 2D CNN) to be used in an American Sign Language (ASL) classification project with video input. This model is deployed via an interactive graphical user interface so that the model acts as an educational tool for users.
This project leverages Artificial Intelligence (AI) to create an educational interface for users first learning ASL. The datasets chosen for this project were those of ethical origins and significant diversity. Existing ASL models have been shown to demonstrate bias through class imbalances and underrepresentation of minority populations. The datasets chosen and the augmentation performed through this project aimed to reduce these common biases. Ultimately, the educational model was created to best represent individuals of all backgrounds, genders, and ages. In integrating well-performing video classification models with balanced and diverse datasets, the implementation of this platform can yield significant, not-yet-achieved benefits to the Deaf community and to all ASL learners.